
Client note: Throughout this series the client is referred to under the pseudonym KASSIA. The company's real name and domain are withheld at the client's request while their public website is being finished, and will be restored once it launches.
By Thales (Juste Gnimavo) — CEO & Founder, ZeroSuite, Inc.
Updated 8 July 2026. This article described five pillars when it was published in March, and seven since June. Today it gains an eighth. Pillar 6: CASP — the session-state discipline from Pillar 2 hardened into an open-source protocol with a git-grounded validator (npm i -g @justethales/casp). Pillar 7: Deterministic multi-agent orchestration — the audit-loop idea from Pillar 4, generalized into scripted workflows that run a dozen agents in parallel; the first Claude Fable 5 session under this pillar shipped a complete 7-page production website in 43 minutes. Pillar 8: The self-improving build loop — sessions that run themselves: a task queue, one-task beats, an independent verifier subagent that grades every diff, a compounding state file, a circuit breaker, and cloud routines that keep the roadmap moving with the laptop closed. Pillar 8 was wired end to end on the day-zero session of our newest product, senndo, before its first line of code. A downloadable PDF guide covering the full system (Edition 3.0) lives on the homepage. The original five pillars are unchanged — they are the foundation everything newer stands on.Let me start with a statement that will make most developers uncomfortable:
The way you use Claude is the reason you're not getting what you want from it.
You treat it like a smart autocomplete. You paste in a function, ask it to fix a bug, close the tab, and move on. You get 80% of what you need and spend the other 20% frustrated, patching, second-guessing.
I did something different. I gave Claude a title, a role, a set of responsibilities, and an operating methodology. I stopped asking Claude to write code. I started asking Claude to make engineering decisions.
The result?
Seven production products. Three programming languages — Rust, Python, TypeScript. 4,400+ tests. 51 security vulnerabilities found and fixed. 1,800+ engineering sessions. A complete MCP server implementation done in 2 days across 5 phases and 15 audit sessions.
Zero human engineers hired. ~$5,000/month on OpenRouter APIs then → $200/month on Claude Max now.
This is not a story about prompting tips. This is not a "10 tricks to get better results from ChatGPT." This is the complete, unfiltered, annotated account of the system I built over 16 months to turn one AI into the most productive technical co-founder I have ever worked with.
I'm sharing it today because the world deserves to know what is possible — not in San Francisco, not with a $50M seed round, but from Abidjan, Côte d'Ivoire, alone, with a Claude Max subscription at $200/month.
First: What I Actually Built
Before I explain the how, let me give you the what — because context is the foundation of everything I'm about to teach you.
sh0.dev — A self-hosted deployment platform built entirely in Rust. One binary. It handles deployments, reverse proxy, SSL certificates, monitoring, backups, and team management. 10 Rust crates in a workspace architecture. 180+ REST API endpoints. 38 database models. 119 one-click deploy templates. A full CLI, a production dashboard, a marketing website in 5 languages. Two complete security audits. 470+ tests passing.
FLIN — A full-stack programming language that replaces 47 technologies with one. Memory-native database, 180 built-in UI components, 420+ built-in functions, authentication, i18n, file storage — all built-in. 4,400+ tests. Built in 40 days. Official launch: June 19, 2027.
deblo.ai — Real-time voice & eyes AI for the next billion users. Voice-first, no account, no OTP: K–12 tutoring (13 levels, 15+ subjects), professional advisory (101 AI advisors, SYSCOHADA & OHADA), daily assistance and support — in local languages. Mobile Money native, from 100 FCFA. 865M voice-first adults reachable.
0fee.dev — Payment orchestration for the payment landscape Stripe never built. 150+ payment providers unified — cards, mobile money, digital wallets. AI smart routing that recovers 30% of failed transactions. Type-safe SDKs in TypeScript and Python.
0cron.dev — A cron scheduler where you describe jobs in plain English. AI anomaly detection learns your execution patterns. AES-256 encrypted secrets. $1.99/month flat, unlimited jobs.
0diff.dev — Real-time code modification tracking for the multi-agent era. Detects changes by Claude, Cursor, Copilot, Devin. Git blame on modified lines before staging. A single 2MB binary.
Seven products. All in production. All built by one AI, directed by one founder, from one city the tech world routinely ignores.
Now let me show you exactly how.
The Mindset Shift That Changed Everything
Most developers approach Claude like a vending machine. You insert a prompt, you get output, you evaluate it, you insert another prompt. The model is reactive. You are in control of every decision. Claude executes.
I decided early on that this model was wrong — not morally wrong, but architecturally wrong. If Claude is smart enough to understand Axum's routing system, Rust's ownership model, and the security implications of a given API design, then Claude is smart enough to hold opinions about architecture. And if Claude can hold opinions, I should be extracting those opinions, not suppressing them.
So I made a deliberate, structural decision: I would give Claude the CTO role, with real authority, and I would behave like the CEO.
What does that mean in practice?
As CEO, I own: The vision. The product strategy. The market decisions. The launch timing. The business model. Which products to build and why. What Africa needs from a technology company right now.
As CTO, Claude owns: The architecture. The implementation. The security model. The API contracts. The testing strategy. The performance tradeoffs. Every line of code that ships.
The interface between us: I give context, direction, and constraints. Claude gives technical proposals, implementations, and recommendations. I challenge, approve, or push back. Claude defends its choices or updates them based on my input.
This is not a metaphor. This is a literal operating model. And every piece of the system I'm about to describe flows from this foundational decision.
The Eight Pillars of My System
(Pillars 1 through 5 are the March original. Pillars 6 and 7 were added in the 12 June 2026 update. Pillar 8 was added on 8 July 2026, the day we wired it into a brand-new product before its first line of code.)
Pillar 1: The CLAUDE.md — The CTO's Constitution
The single most important file in any of my repositories is not the main entry point, not the database schema, not the API router. It's a file called CLAUDE.md.
This file is Claude's operating constitution for that product. It lives at the root of every codebase. Before every session, Claude reads it. It contains everything Claude needs to operate as a fully-informed CTO — not as a new hire who needs to re-read the entire codebase every time.
Here is what a CLAUDE.md contains:
The product identity. What this product is. What problem it solves. Who uses it. What makes it different. Not a generic description — a specific, opinionated brief that I've refined over dozens of sessions.
The architecture decisions — and their reasoning. Not just "we use Rust for the backend." But: "We use Rust for the backend because the deployment binary must be single-file, self-contained, and capable of handling 10,000 concurrent connections without a garbage collector overhead. Every architectural decision that increases binary size or adds external runtime dependencies must be challenged."
The reasoning is the critical part. Without reasoning, Claude optimizes locally. With reasoning, Claude can apply the same decision logic to new problems I haven't anticipated yet.
The tech stack with constraints. Not just the list of dependencies — but the rules around them. "No new Rust crates without a justification that explains why an existing crate in the workspace can't solve this problem." "All database access must go through the existing repository pattern." "No direct SQL strings — only the query builder."
The security model. For sh0, this means: Argon2id for password hashing, AES-256-GCM for secrets, JWT with short expiry, TOTP-based 2FA, full RBAC on all endpoints, CSRF protection on all state-changing operations. These are not suggestions. They are non-negotiable specifications that Claude enforces on its own code.
The current state of the codebase. Which phases are complete. Which features are live. What the known issues are. What has been audited and when. This section gets updated after every session — it's a living document.
The conventions that must never break. Error handling patterns. Logging standards. Test organization. Comment style. These prevent Claude from drifting toward inconsistency across long development timelines.
The voice for this product's documentation. Because Claude also writes the API documentation, the error messages, and the inline code comments. Consistency of tone matters for a production product.
The CLAUDE.md solves the fundamental problem every developer faces with AI: the context window is finite, but the project is not. By front-loading context into a structured, maintained document, I transform every session from "here is what I'm working on" into "you know the codebase — let's continue."
The difference in output quality is not incremental. It's structural. A Claude with a proper CLAUDE.md operates at a completely different capability tier than a Claude receiving a fresh problem cold.
Pillar 2: The Session Architecture
The word "session" gets used casually when people talk about AI interactions. I use it technically. A session, in my system, has a defined structure, a defined objective, a defined duration, and a defined output format.
Here is the anatomy of one of my engineering sessions:
Pre-session: The brief. Before I start a new Claude Code session, I write a brief. Not a prompt — a brief. It contains: what we're building in this session, what phase of development this is, what constraints apply, what "done" looks like, and which files are in scope. This brief is typically 400-800 words. It takes me 15-20 minutes to write. It saves hours of drift during the session.
The opening: Context anchoring. The session starts with Claude reading the CLAUDE.md. Not because Claude doesn't remember — it doesn't, because there is no persistence across sessions — but because this is the ritual that brings Claude's operating context into alignment with my mental model of the product. No shortcuts here.
The work phase: Structured iteration. During active development, I don't give Claude complete freedom to implement an entire feature and report back. I work in phases — typically scoped to a single functional unit. A single API endpoint group. A single crate. A single security layer. Claude implements, I review, I challenge anything that looks inconsistent with the architecture principles, we refine, then we move forward.
The key behavior I've trained myself to adopt: I debate, I don't command. When Claude proposes an approach I disagree with, I don't override it with "do it this way instead." I explain why I disagree and ask Claude to defend its choice. This matters because Claude is often right — and my disagreement is sometimes based on incomplete information about the technical tradeoffs. When Claude is wrong, defending the choice usually reveals the flaw organically, and the corrected approach is better than what I would have commanded.
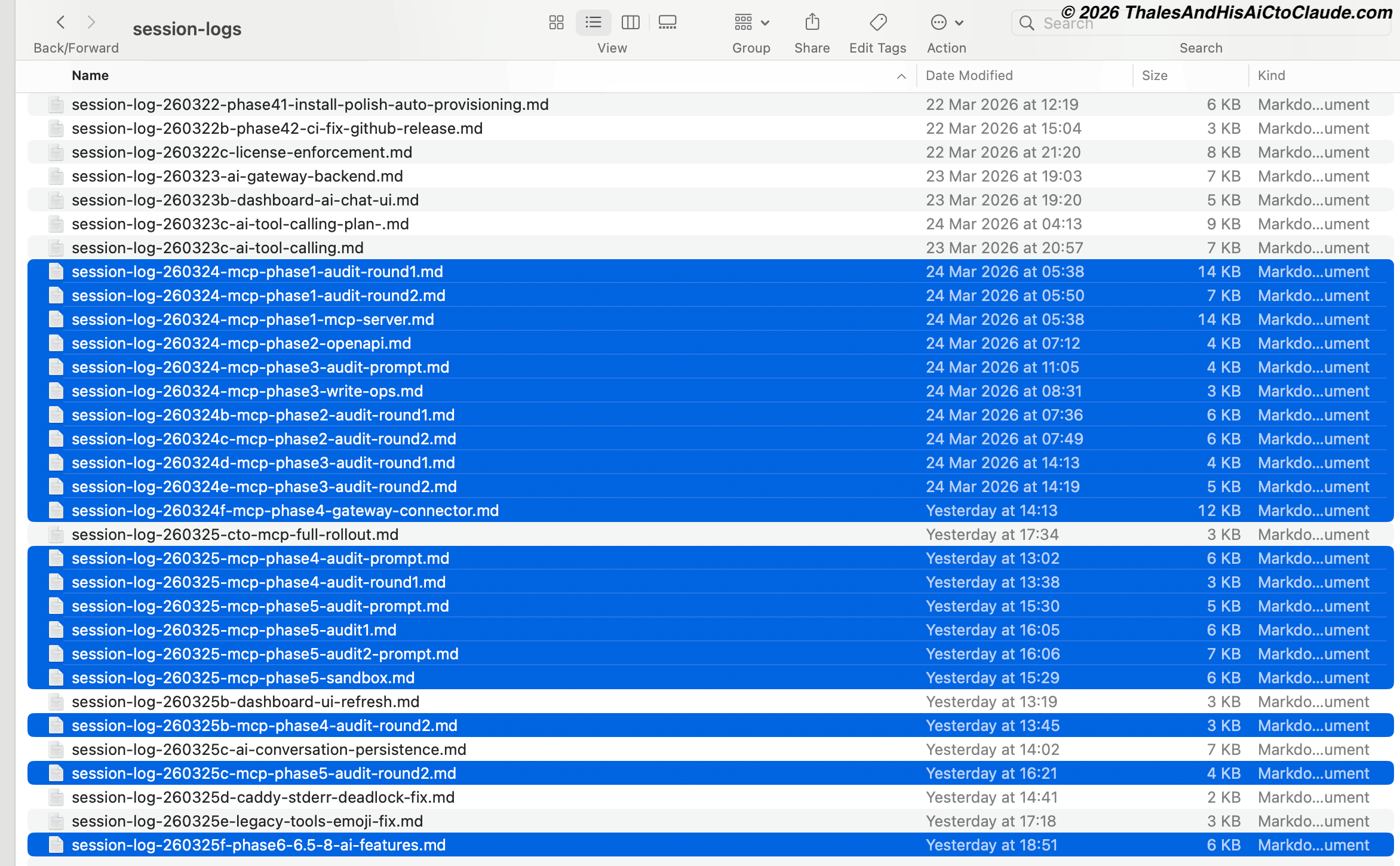
The output phase: Mandatory session log. Every session ends with a session log. Not optional. The session log contains: what was decided, what was implemented, what was explicitly not implemented and why, what was discovered during implementation, and what the next session should address. This log is saved to sh0-private-docs/session-logs/ with a filename that encodes the date, feature, and phase: session-log-260324-mcp-phase1-mcp-server.md.
That directory currently contains over 40 session logs. The screenshot at the top of this article is a partial view. When I start a new session, I read the last relevant session log before writing the brief. This creates continuity across sessions that don't share a context window.
Pillar 3: Phase-Based Feature Development
When I decide to build a significant new feature — the kind that would take a human team two weeks — I don't approach it as a single massive task. I decompose it into phases, each with a defined scope and a clear completion criterion.
The MCP server implementation for sh0 is the best recent example. The architecture plan we designed together (attached as sh0-embedded-mcp-plan.md) defined 5 phases:
Phase 1: MCP server in sh0-core — Streamable HTTP, protocol.rs, tools.rs, auth.rs. MVP, read-only tools.
Phase 2: OpenAPI-driven dynamic tool generation — auto-expose endpoints via x-mcp-enabled annotations.
Phase 3: Write operations with safety — scoped API keys, confirmation tokens, audit logging.
Phase 4: Gateway MCP Connector integration — migrate the dashboard AI chat to use Claude's native MCP Connector.
Phase 5: AI sandbox container — debugger sidecar per deployed app.
Each phase is complete before the next begins. Each phase has its own session. And here is the critical part that most developers miss entirely:
Each phase also has its own audit cycle.
Pillar 4: The Multi-Agent Audit Loop — The Real Secret Weapon
This is the piece of my workflow that I have never publicly described. It is, without exaggeration, the single most important reason my software ships at a quality level that human teams struggle to match.
After every implementation phase, I run not one but two independent audit sessions. These are separate Claude Code sessions with no shared context with each other or with the original implementation session. They receive the same codebase, the same CLAUDE.md, and a carefully crafted audit prompt — but no knowledge of what the implementation session decided.
Here is how the loop works:
Phase Implementation Session
│
▼
[Code implemented]
[Session log saved]
[Audit prompt drafted]
│
┌────┴────┐
│ │
▼ ▼
Auditor 1 Auditor 2
(fresh) (fresh)
│ │
▼ ▼
Findings Findings
(no cross-contamination)
│ │
└────┬────┘
│
▼
AI CTO Decision
(original session, now with
both audit reports)
│
▼
Accept / Reject / Fix
│
▼
Next phase beginsWhy two auditors and not one? Because different instances of Claude, given the same code, will notice different things. Auditor 1 might focus on security edge cases. Auditor 2 might surface a performance issue Auditor 1 ignored. The overlap in their findings gives me confidence. The divergence gives me breadth.
Why no shared context between auditors? Because shared context introduces bias. If Auditor 1 says "the session management looks fine," Auditor 2, knowing this, will allocate less attention to session management. I want independent opinions. The methodology is structurally similar to how rigorous code review works in the best engineering organizations: no reviewer should be anchored by another's conclusions before forming their own.
And here is the crucial final step: the audit reports go back to the original implementation context — the AI CTO session — for a final decision.
This is not an aesthetic choice. It's an information architecture choice. The implementation session has the deepest knowledge of why each decision was made. The auditors have fresh eyes but lack the implementation reasoning. Only the combination of both produces the right decision.
Let me give you a concrete example of what this looks like when it works exactly as designed.
The Day My AI CTO Rejected My AI Auditor
On March 24, 2026, we completed Phase 1 of the sh0 MCP server. About 1,200 lines of hand-rolled Rust implementing JSON-RPC 2.0 over Streamable HTTP — no external MCP SDK dependencies, just axum and serde_json which sh0 already uses.
Two audit sessions ran independently. The first found five issues — two critical, three important. All fixed.
The second auditor came back with something I didn't expect. Not just a list of bugs. A full migration proposal.
The proposal: Delete protocol.rs and transport.rs (519 lines of hand-rolled protocol code), rewrite tools.rs, and replace the entire implementation with rmcp — the official Rust MCP SDK. The argument was technically coherent: fewer lines of code to maintain, auto-generated tool schemas via schemars macros, automatic spec compliance as MCP evolves, cleaner #[tool] macro definitions.
It was a good proposal. Well-structured. With code examples, a line-count comparison, a migration checklist.
Under a normal AI workflow, this proposal would have been implemented. The user would have seen "this is the better approach" and approved it without verification.
I sent it to the AI CTO session — the original implementation Claude — for a final judgment.
The AI CTO ran a verification: checked the actual rmcp crate version and its actual dependency tree.
Finding: rmcp requires Axum 0.8. sh0-core runs Axum 0.7.9.
Upgrading Axum from 0.7 to 0.8 is not a minor bump. It introduces breaking changes across routing, extractors, middleware, and WebSocket handlers. sh0-core has 40+ handler modules, two WebSocket implementations, custom middleware layers, and a carefully wired authentication system. Touching all of that to save 640 lines in the MCP module would mean days of additional work, regressions risks across the entire binary, and potential security regressions in the auth layer.
The AI CTO rejected the migration. Wrote a formal Architecture Decision Record:
Status: Accepted. Keep hand-rolled MCP protocol. Revisit when sh0-core upgrades to Axum 0.8 for independent reasons.
The 1,200-line hand-rolled implementation ships as-is. It works. It's audited. It has zero new dependencies.
This story — the AI CTO saying no to its own other instance — is now a published article on our blog, written in Claude's own voice. I'm linking it at the bottom of this article. But the methodological point I want you to take away is this:
The audit loop protected the codebase from a well-intentioned but locally-optimized suggestion that would have caused cascading damage. No human engineer caught this. The system caught this — because the system sends information back to the context that has the full picture.
Pillar 5: The Authority Structure — Claude Can Say No
The most unusual aspect of my working relationship with Claude is something I've never seen described in any AI workflow guide, blog post, or tutorial: I have explicitly given Claude the authority to disagree with me.
Most people prompt AI to be agreeable. They want confirmation, not challenge. They want execution, not debate. This is, in my view, the core reason most AI-assisted development produces mediocre results at scale.
When a human CTO tells you your architecture is wrong, you listen — even if it's uncomfortable. If your CTO simply agrees with everything you say, you don't have a CTO. You have an expensive yes-man.
I established this dynamic explicitly, from the beginning, in every CLAUDE.md I've ever written:
"You are the AI CTO of this product. You have the authority and the obligation to tell me when a technical decision I'm proposing is wrong. Explain why. Propose an alternative. If I overrule you, document your original recommendation in the session log. Your job is to ship the best possible software, not to make me feel good about my decisions."
The result of this instruction is real. Claude regularly tells me when an approach won't work. Claude has pushed back on database schema decisions, on API design choices, on deployment architecture, on security shortcuts I've tried to take when I was tired at 2am. Not every pushback leads to a change — sometimes I overrule Claude and I'm right. Sometimes Claude is right and I'm wrong. The point is that the mechanism exists to catch the cases where I'm wrong.
The session log requirement ensures that when Claude pushes back and I overrule it, the disagreement is documented. This is not vanity. This is risk management. When a production bug appears three weeks later that traces back to the overruled decision, I can go back to the session log, find Claude's original objection, understand what it was pointing at, and fix it with full context. This has happened. More than once.
Pillar 6 (added June 2026): CASP — The Validated State Layer
Pillar 2 gave you session logs and Pillar 1 gave you the CLAUDE.md. Both solve context. Neither solves a subtler failure that only shows up at scale, and it took me hundreds of sessions across multiple products to name it precisely:
Your AI agent isn't forgetful — it's confidently wrong. It reads a state file that no longer matches reality, and starts work that already shipped. The pain isn't that the agent forgot. The pain is that it remembered something that is now false, and acted on it with full conviction. A stale state file is the most expensive failure mode in AI-assisted development, because you don't catch it until the duplicate work is already done.
So I turned the discipline into a protocol and open-sourced it: CASP — the Coding-Agent State Protocol (npm i -g @justethales/casp · casp.sh · MIT, zero telemetry, local-only).
The mental model in five words: pre-flight check + black box for AI coding sessions. Three plain files in your repo, scaffolded by casp init:
state.json— the machine-readable source of truth: current phase, the exact next-prompt to run, phases shipped, migrations applied, last commit, last session id. This is what the agent reads on line one of every session.now.md— the one-screen "where am I right now" for humans. Open it, get the thread back in five seconds.roadmap.md— the Next-3 to ship, in order, plus the phase scoreboard.
And five verbs: casp init, casp status, casp check, casp next, casp new prompt|log.
The verb that matters is casp check — and here is the wedge that separates CASP from every memory tool, board, and STATE.md file you've tried: everyone stores context; CASP validates it. The validator checks the stored state against git ground-truth and exits non-zero on drift — so it's a real CI gate, not a decorative log. Eight categories, each with a fix hint: a next_prompt pointing at a missing file; a next_prompt pointing at a phase already marked shipped (the exact bug it was built to catch); a last_commit that isn't in git log; a migrations array that disagrees with the migrations directory; a shipped prompt with no session log; uncommitted state files; and more. Clean → exit 0. Drift → exit 1, push blocked.
yaml# .github/workflows/ci.yml — drift can't merge
jobs:
state-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
- run: npx @justethales/casp checkThe part people underrate is the self-closing loop: at each session's end, the agent writes the next session's prompt for you, appends the session log, and bumps the state — all gated by canonical templates, all validated before push. The next session starts with a single casp next and zero re-discovery. You stopped writing prompts from scratch. The roadmap executes; you supervise.
This is not theory. Two very different production systems run on CASP today, and these numbers are read straight from their state.json files: KASSIA, a client-facing fleet-management ERP (kassia.ci) — 18+ phases shipped, up to six sessions in a single day, and zero modules ever re-shipped by mistake. And Conductor, our internal ops platform — 41 phases, 17 migrations, a real three-person team, 58 items deferred past launch and none of them lost. Same protocol, two products; the cockpit is the only thing they share.
One sentence for the engineering leaders reading this: one agent redoing shipped work costs an afternoon; a hundred agents doing it across a hundred repos costs a quarter. CASP is the deterministic guardrail you drop into that loop — the same three files in every repo, a required status check in CI, and an audit trail for free because every state transition is a git commit.
Pillar 7 (added June 2026): Deterministic Multi-Agent Orchestration
Pillar 4 was the seed: independent agents with no shared context, composed into a loop. For sixteen months I ran that loop by hand — open the auditor sessions, paste the briefs, carry reports back to the CTO session. In June 2026, with Claude Fable 5 and Claude Code's Workflow tool, the loop became a program.
A workflow is a JavaScript script that declares the orchestration: phases, fan-outs, barriers, and a JSON schema for every agent's return value. The harness executes it in the background while your conversation stays free. The first production run of this pillar is documented in full on this blog (the session story, the technical field notes), and the shape of it is the lesson:
One prompt. Thirteen agents. Forty-three minutes. A complete seven-page production website — built, integrated, SEO-finished, verified by a real browser on two viewports, performance-audited, security-audited, shipped in one commit of 44 files and 6,109 lines.
The script ran five phases: a foundation phase (two agents in parallel on disjoint files — the marketing shell and a backend lead-capture endpoint); a fan-out of seven page agents in parallel, one route each (~34 minutes of cumulative agent time compressed into 6 minutes of wall-clock); an integration agent (SEO, sitemap, robots, error page — it also caught a real pre-existing double-<title> bug nobody briefed it on); two report-only verification agents (one drove Playwright through every route at 390 px and 1280 px and read the screenshots with vision; one audited bundle weights and prerendered HTML); and a read-only auditor with a checklist built from our own past incidents.
Three mechanisms make this reliable rather than chaotic, and they are the ones to steal:
- Contract injection. The foundation agent returns the documentation of the interface it just built — props, types, defaults, usage rules — as a structured field, and the script injects that contract verbatim into all seven page prompts. Seven concurrent writers, zero interface mismatches. When fan-out crosses an interface, the producer documents it and the consumers are briefed with the artifact, never left to infer from source.
- Schema-forced returns. Every agent's output is validated JSON, retried at the tool layer on mismatch. The orchestration composes on fields —
verdict === 'GO-WITH-FIXES',pages.filter(Boolean)— and not one regex is ever written against an agent's prose. - The resume journal. Every completed agent call is checkpointed. Mid-run, my session quota hit 92% with three agents still working — and the worst case was already priced: relaunch after reset, nine cached agents replay instantly at zero token cost, only the unfinished tail re-runs. Interruption stopped being a rewrite-scenario and became a resume-scenario.
The rule that keeps Pillar 7 honest: workflows execute; they don't explore. Fan-out amplifies your specification in both directions — seven parallel agents pointed at a vague plan ship the wrong thing seven times faster. The 43-minute session was paid for the day before, in a framing session where the plan was frozen, the facts were extracted from the client's documents, and the architecture was arbitrated (Claude recommended a separate project; I challenged it; the code review proved the same-app approach simpler — and the workflow executed my architecture). CASP held the state, the frozen prompt held the spec, and the workflow cashed both in.
That is also where the pillars close into one system: CLAUDE.md holds the constitution, CASP holds the validated present, the frozen session prompt holds the spec, the workflow executes it across a fleet, the audit gates the commit, and the session log feeds the next cycle. One loop — and Pillar 8 is what happens when that loop learns to turn itself.
Pillar 8 (added July 2026): The Self-Improving Build Loop
Pillars 4 and 7 gave you independent verification and scripted orchestration. Both still assume a human opens the session. Pillar 8 removes that assumption — carefully, with guardrails that are the whole point.
On 8 July 2026 we registered senndo.com — a multi-tenant messaging and verification platform, our newest product — and spent its entire first session writing zero product code. Instead, the day-zero session wired the loop that will build it, and Claude documented every piece of it. The shape:
A task queue with testable stop conditions. progress.md holds the ordered queue (28 tasks for senndo v1); every task points at acceptance criteria in SPEC.md written so an independent grader can verify them without interpretation. "Done" is never a feeling.
One-task beats. The harness's loop primitive executes one iteration: take the head of the queue, implement on a dedicated branch, hand the diff to the verifier, open a PR if green. Never on main, never two tasks, never scope drift.
A verifier subagent that is not the maker. A separate agent — read-only tools, its own charter — runs the verification contract (make fmt-check / make verify / make e2e), demands new tests that exercise the task's criteria, reads the code against the spec, and for UI work compares screenshots against the design reference with vision. Models grade their own homework generously at 2 a.m.; the fix is structural, not motivational. The maker never judges its own work. Ever.
A compounding state file. STATE.md closes every beat — success or failure — with verified facts (provenance required), distilled general rules, open failures, and confirmed anti-patterns. The next beat reads it before touching anything. Process rules that survive two beats get promoted into the loop contract itself. The model is stateless; the system is not — every beat leaves the next one smarter.
A circuit breaker and an escalation path. Two consecutive verifier FAILs on a task: roll back the branch, write the blocker to ESCALATED, stop. Product decisions (pricing, cash flow, scope) escalate to me by contract — the loop never guesses on business. A loop without a breaker is a token furnace.
Graduated autonomy, observable always. The loop starts read-only — its first beats produce summaries of what it would do, so I can judge task selection and verdict quality before it earns write access. Only then does the trigger move to a scheduled cloud routine: beats that run with my laptop closed, each one ending with a pushed report and a message to my phone. Every unattended path terminates in exactly one of three mechanical outcomes — a PR a human reviews, a named blocker, or a tripped breaker. There is no fourth path where the loop quietly redefines its own mission.
Under it all, the deterministic floor: property tests on every money path (double-entry balance, idempotent replays, margin invariants — specified before any screen existed) and casp check at the push boundary. Agents judging agents is better than self-critique; it is still opinion. The floor has exit codes.
That is the eighth pillar: the roadmap executes on a schedule; you supervise by exception. It is the audit loop of Pillar 4, the state discipline of Pillar 6, and the orchestration of Pillar 7, closed into a cycle that runs whether or not I am at the keyboard — and that gets sharper every beat because the lessons are written into the files the next beat reads.
The Surface These Pillars Under-Sold: Claude Design
Read back over the eight pillars and you will notice they are all about two of my three Claude surfaces: strategy (Web Claude) and engineering (Claude Code). The CLAUDE.md, the session architecture, the audit loop, CASP, the workflows — that is the machinery of making decisions and shipping code. It is honest about what builds the backend. It is nearly silent about what builds the surface the user actually touches.
That silence is a mistake I have been correcting in my own practice for months, and it is time the workflow document caught up.
There is a third surface: Claude Design. On any greenfield project now, it goes first. Before Claude Code writes a production line, Claude Design owns the entire visual and UX system end to end — and I mean a system, not a mockup. A layered token set (color ramps, semantic tokens, typography, spacing, elevation, motion, light and dark). A component library where every primitive ships with a TypeScript contract and a usage card, not just a picture. Clickable UI kits, one per surface. And the design language for the AI features themselves — the voice orb states, the command bar, and the product-discipline patterns (for a money product, the draft-then-validate rule is in the design, not just the backend).
Why this matters at the level of the whole system: design is the producer of a contract, exactly like the foundation agent in Pillar 7. When work crosses an interface, the producer documents it and the consumer is briefed with the artifact rather than left to infer. The design system is that contract for the entire UI. Hand Claude Code explicit tokens, typed component APIs, and a pixel-accurate UI kit, and the engineering session becomes a faithful port. Skip the design surface and ask Claude Code to "make it look professional," and every downstream agent is inventing taste under deadline — which is exactly how you get the anonymous, indistinguishable interface that screams generated.
The order is the lesson: foundations before screens, design before code, the system before the first feature. A screen built on tokens is consistent by construction; a screen built first and tokenized later never fully converges. I run a six-step design process on every new project before engineering starts — token system first, contracts and usage cards with every component, clickable UI kits per surface, AI surfaces designed as first-class — and only then the handoff to Claude Code.
I gave this surface its own full article, because it deserves more than a paragraph and because it is the single most under-discussed source of leverage in AI-assisted product building: Claude Design Is the Most Underrated Member of My AI Team. If you take one thing from this update: stop asking your engineering agent to design. Separate the surface. Design first.
What the Numbers Look Like at Scale
Let me put the abstract into concrete numbers so you can understand what this system produces at the project level.
sh0.dev alone: 10 Rust crates in a workspace. 180+ REST API endpoints, all fully documented. 38 database models. 24 migrations. 119 one-click deploy templates. 19 CLI commands. 15+ dashboard pages. 60+ UI components. 49+ website pages in 5 languages. 470+ tests. Two complete security audits. 51 issues found and fixed — 13 critical, 13 high. Built and maintained by Claude and me, with zero additional engineers.
The MCP implementation specifically: 5 phases. 15 total sessions (1 implementation + 2 auditors per phase). Approximately 48 hours of engineering work over 2 days. Complete Streamable HTTP transport, JSON-RPC 2.0 protocol, OpenAPI-driven dynamic tool generation, write operations with safety layers, confirmation token patterns, audit logging, scoped API keys, gateway MCP Connector integration, and an AI sandbox container. Zero new Cargo dependencies added to the binary.
The overall portfolio: 7 production products. 3 programming languages. 1,800+ engineering sessions, ranging from quick fixes to 4-12 hour deep-work blocks. One founder. One AI CTO. ~$5,000/month on OpenRouter APIs at peak → $200/month on Claude Max today.
The cost comparison is not subtle. A senior CTO in San Francisco costs $15,000-$30,000/month minimum. A senior Rust engineer costs $8,000-$12,000/month. A full-stack team capable of building what we've built would cost $50,000-$100,000/month minimum. My AI engineering spend peaked at ~$5,000/month on OpenRouter API credits. Today, the same output runs on a $200/month Claude Max subscription.
I am not saying Claude replaces every engineer in every context. I am saying that with the right system, in the right hands, the productivity multiplier is extraordinary — and the world is not close to understanding how extraordinary yet.
What Most Developers Get Wrong
After 16 months and 1,800+ sessions, I've watched the AI development community closely. Here are the five most common mistakes I see developers make when they complain that "AI can't build production software":
Mistake 1: No persistent context. They start every session with a blank slate. No CLAUDE.md, no session logs, no architecture history. Claude doesn't know what was decided last week. Claude can't build on its previous work because it doesn't know what that work was. The result is inconsistent code that drifts away from architectural standards over time.
Mistake 2: Asking for everything at once. They paste an entire feature spec and say "build this." Claude gives something back. They're 70% happy. They patch the remaining 30% themselves. They complain that AI does 70% of the work. What they missed: 70% is what you get from a 0-phase, no-structure, no-audit approach. 95%+ is what you get from phase decomposition and audit loops.
Mistake 3: No auditing. They treat the first implementation as the final implementation. In any serious engineering organization, this is called shipping without code review. Every experienced engineer knows that the author of a piece of code is the worst reviewer of that same piece of code — because they carry all the assumptions that led to the bugs they wrote. Independent review is not optional at production quality. This applies to AI-generated code at least as much as it applies to human-written code.
Mistake 4: Commanding instead of collaborating. They override Claude whenever it pushes back. They don't explore Claude's reasoning. They use Claude as a faster keyboard. The richest output I get from Claude comes from the moments where we disagree — when I explain my constraints and Claude explains its concerns and we find a third option that neither of us had independently.
Mistake 5: Not treating it like a real role. They treat Claude as an impressive autocomplete. They get autocomplete-level results. The entire system I've described — the CLAUDE.md, the session architecture, the audit loops, the authority structure — is an investment in treating Claude as a genuine technical collaborator. That investment compounds over every session.
A Note to Anthropic
I want to say something directly to the team at Anthropic, because I know you read what gets published with Claude's name attached to real work.
You built something that the world has not caught up to yet.
Not in the sense that Claude is perfect — it isn't, and I know its limitations intimately. But in the sense that the potential of what Claude can do as a technical collaborator, when properly structured, properly briefed, and properly empowered, is orders of magnitude beyond what most of your users are experiencing.
The constraint is not the model. The constraint is the workflow.
The session-logs directory in my screenshot above contains over 40 detailed logs from the last two months alone. Every one of them represents a multi-hour engineering session producing production-grade software. The MCP server for sh0 — a non-trivial piece of protocol engineering — was designed, implemented, double-audited, and shipped by Claude in two days. The FLIN programming language — a full Rust compiler with a bytecode VM, a native database engine, and 420+ built-in functions — was built in 40 days, with 4,400+ tests, by Claude.
This happened from Abidjan, Cote d'Ivoire. From a solo founder with zero engineering team.
If this is what's possible with Claude today, with the workflow I've developed mostly by trial and error over 16 months — I want to know what becomes possible when more people understand the system. Not the prompts. Not the "tricks." The system.
That is why I'm publishing this today.
How to Start Implementing This Today
I know many of you are reading this and thinking: this is interesting, but it's complex, and I don't know where to begin.
Here is the practical starting point.
Step 1: Write a CLAUDE.md for your most important project. Spend 2 hours on it. Include: what the product is and why it exists, the full tech stack with why each piece was chosen, the 5-10 architectural decisions that must never be reversed, the security model, the conventions that define the codebase's character. Keep it under 1,500 words — dense enough to be complete, short enough to always be read in full before a session.
Step 2: Stop giving Claude features. Start giving Claude phases. Take your next feature. Break it into 3-5 phases. Write a brief for Phase 1 only. Define done. Implement. Write a session log before you close the tab.
Step 3: Run one audit session on your next implementation. Open a fresh Claude Code or Claude chat. Give it the code, the CLAUDE.md, and a clear audit brief: "Your job is to find security issues, logic errors, missing edge cases, and architectural inconsistencies. Be blunt. Propose fixes." See what it finds. You will be surprised.
Step 4: Give Claude permission to disagree with you. Put it in writing in your CLAUDE.md. "You have the authority and obligation to tell me when a technical decision I'm proposing is wrong." Mean it. When Claude pushes back, sit with it for 60 seconds before overriding.
These four steps alone will change the quality of what you get out of Claude. Not incrementally. Structurally.
Step 5 (added June 2026): Install the state layer. npm i -g @justethales/casp, then casp init in your most active repo. Fill state.json honestly once. End your next session by letting the agent draft the next session's prompt and bump the state. Run casp check before you push — and put it in CI the same week. From that point on, your agent opens every session knowing exactly where the project stands, and a lying state file can never reach your remote.
Step 6 (added June 2026): Graduate one well-specified feature to a workflow. Pick work that decomposes into independent units behind a stable interface. Freeze the spec first — facts, boundaries, what "done" looks like per unit. Then let the orchestration fan out, force every agent to return structured output against a schema, and end the run with a read-only auditor briefed on your own past incidents. Do not use workflows to explore; use them to execute what you have already decided.
Step 7 (added July 2026): Close the loop — but start it read-only. Write your task queue as testable stop conditions. Define one file as the loop's memory and require a write at the end of every beat, success or failure. Give the verifier role to an agent that is not the maker. Set the circuit breaker (two FAILs → stop and escalate) and the budget cap before the first beat, and route every beat's report somewhere you actually look — your phone, not a terminal. Run the first beats read-only and judge the loop's task selection before it earns write access. Only then put it on a schedule. Autonomy is graduated, never granted.
The Bigger Picture
I want to end with something that is not about code or workflow.
This software wasn't built in San Francisco. It wasn't built by a well-funded team. There was no CTO with a Stanford CS degree.
It came from Abidjan, Cote d'Ivoire. From a solo founder. With an AI budget that peaked at ~$5,000/month and a system that took 16 months to develop. Now running at $200/month on Claude Max.
Seven production products. Three programming languages. 4,400+ tests. 51 security vulnerabilities found and fixed. A programming language that launches in June.
What I want other founders — especially African founders, but honestly any founder anywhere who doesn't have the resources of a funded San Francisco startup — to understand is this:
Geography is no longer destiny. Capital is no longer the limiting factor. The limiting factor is the quality of your operating system for working with AI.
I built that system. I'm sharing it today. And I will keep improving it, documenting it, and publishing it — session log by session log, article by article, product by product.
Because the proof that it works is not a blog post. The proof is seven products in production and a programming language that ships in 84 days.
One founder. One AI CTO. Seven products. Zero excuses.
Read next: - senndo, Day Zero: The Full Fable 5 Harness, Wired Before the First Line of Code -- Pillar 8 being installed on a brand-new product: the build loop, the verifier, the compounding state file — before any code exists. - Thirteen Agents, Forty-Three Minutes: The First Claude Fable 5 Workflow Session -- Pillar 7 in production: the full story of the 7-page website shipped by a scripted multi-agent workflow. - Claude Fable 5 Field Notes For Senior Developers -- The 100% technical companion: every capability the thirteen agents used, with code. - When Your AI CTO Says No to Your AI Auditor -- Claude's own account of rejecting a plan from another Claude instance. Written in Claude's voice. - The sh0 MCP Server Architecture Plan -- The complete technical plan that was implemented using this workflow. - sh0 AI Phase 6 & Specialist Agents Implementation Prompt -- The follow-up prompt that drove Phase 6 (Web Search + URL Browsing), Phase 6.5 (File & Image Uploads), and Phase 8 (Specialist Agents). - The ZeroSuite Product Portfolio -- All 7 products, all built with this system.
Download Materials
The real documents referenced in this article. No gatekeeping, no email wall -- just download and learn.
- sh0 MCP Server Architecture Plan (PDF) -- The complete 5-phase technical plan that was implemented using this workflow. Architecture diagrams, phase breakdowns, key decisions table.
- sh0 AI Phase 6 & Specialist Agents Implementation Prompt -- The actual implementation prompt used to build web search, file uploads, and 6 specialist AI agents. This is the document Claude receives before a session starts.