
Nota sobre el cliente: A lo largo de esta serie, el cliente se menciona bajo el seudónimo KASSIA. El nombre real de la empresa y su dominio se mantienen en reserva a petición del cliente mientras se termina su sitio web público, y se restituirán en cuanto se lance.
Por Thales (Juste Gnimavo) -- CEO y Fundador, ZeroSuite, Inc.
Actualizado el 8 de julio de 2026. Este artículo describía cinco pilares cuando se publicó en marzo, y siete desde junio. Hoy gana un octavo. Pilar 6: CASP -- la disciplina de estado de sesión del Pilar 2, endurecida en un protocolo open source con un validador anclado en git (npm i -g @justethales/casp). Pilar 7: orquestación multi-agente determinista -- la idea del ciclo de auditoría del Pilar 4, generalizada en workflows programados que ejecutan una docena de agentes en paralelo; la primera sesión de Claude Fable 5 bajo este pilar entregó un sitio web de producción completo de 7 páginas en 43 minutos. Pilar 8: el ciclo de construcción que se mejora a sí mismo -- sesiones que se ejecutan solas: una cola de tareas, beats de una sola tarea, un subagente verificador independiente que califica cada diff, un archivo de estado que se acumula, un circuit breaker, y rutinas en la nube que mantienen el roadmap en movimiento con el portátil cerrado. El Pilar 8 se cableó de extremo a extremo en la sesión de día cero de nuestro producto más reciente, senndo, antes de su primera línea de código. Una guía PDF descargable que cubre el sistema completo (Edición 3.0) vive en la página de inicio. Los cinco pilares originales no han cambiado -- son la base sobre la que se apoya todo lo más nuevo.Permítanme comenzar con una declaración que incomodará a la mayoría de los desarrolladores:
La forma en que usas Claude es la razón por la que no obtienes lo que quieres de él.
Lo tratas como un autocompletado inteligente. Pegas una función, le pides que corrija un error, cierras la pestaña, y sigues adelante. Obtienes el 80% de lo que necesitas y pasas el otro 20% frustrado, parcheando, cuestionando.
Yo hice algo diferente. Le di a Claude un título, un rol, un conjunto de responsabilidades, y una metodología operativa. Dejé de pedirle a Claude que escribiera código. Empecé a pedirle a Claude que tomara decisiones de ingeniería.
¿El resultado?
Siete productos en producción. Tres lenguajes de programación -- Rust, Python, TypeScript. Más de 4.400 tests. 51 vulnerabilidades de seguridad encontradas y corregidas. Más de 1.800 sesiones de ingeniería. Una implementación completa de servidor MCP hecha en 2 días a lo largo de 5 fases y 15 sesiones de auditoría.
Cero ingenieros contratados. ~$5.000/mes en APIs de OpenRouter antes → $200/mes en Claude Max ahora.
Esta no es una historia sobre consejos de prompts. Esto no es "10 trucos para obtener mejores resultados de ChatGPT." Este es el relato completo, sin filtros, anotado, del sistema que construí durante 16 meses para convertir una IA en el co-fundador técnico más productivo con el que he trabajado.
Lo comparto hoy porque el mundo merece saber lo que es posible -- no en San Francisco, no con una ronda semilla de $50M, sino desde Abiyán, Costa de Marfil, solo, con una suscripción Claude Max a $200/mes.
Primero: lo que realmente construí
Antes de explicar el cómo, permítanme darles el qué -- porque el contexto es la base de todo lo que estoy a punto de enseñarles.
sh0.dev -- Una plataforma de despliegue auto-hospedada construida enteramente en Rust. Un solo binario. Maneja despliegues, proxy inverso, certificados SSL, monitoreo, respaldos y gestión de equipos. 10 crates de Rust en una arquitectura de workspace. Más de 180 endpoints REST API. 38 modelos de base de datos. 119 plantillas de despliegue con un clic. Un CLI completo, un dashboard de producción, un sitio web de marketing en 5 idiomas. Dos auditorías de seguridad completas. Más de 470 tests pasando.
FLIN -- Un lenguaje de programación full-stack que reemplaza 47 tecnologías con una. Base de datos nativa en memoria, 180 componentes UI integrados, más de 420 funciones integradas, autenticación, i18n, almacenamiento de archivos -- todo integrado. Más de 4.400 tests. Construido en 40 días. Lanzamiento oficial: 19 de junio de 2027.
deblo.ai -- IA de voz y visión en tiempo real para los próximos mil millones de usuarios. Voice-first, sin cuenta, sin OTP: tutoría K–12 (13 niveles, 15+ materias), asesoría profesional (101 asesores IA, SYSCOHADA y OHADA), asistencia diaria y soporte — en lenguas locales. Mobile Money nativo, desde 100 FCFA. 865 millones de adultos «voice-first» alcanzables.
0fee.dev -- Orquestación de pagos para el panorama de pagos que Stripe nunca construyó. Más de 150 proveedores de pago unificados -- tarjetas, mobile money, monederos digitales. Enrutamiento inteligente con IA que recupera el 30% de transacciones fallidas. SDKs con tipado estricto en TypeScript y Python.
0cron.dev -- Un programador de tareas cron donde describes los trabajos en lenguaje natural. Detección de anomalías con IA que aprende tus patrones de ejecución. Secretos encriptados con AES-256. $1,99/mes plano, trabajos ilimitados.
0diff.dev -- Rastreo de modificaciones de código en tiempo real para la era multi-agente. Detecta cambios por Claude, Cursor, Copilot, Devin. Git blame en líneas modificadas antes del staging. Un solo binario de 2MB.
Siete productos. Todos en producción. Todos construidos por una IA, dirigida por un fundador, desde una ciudad que el mundo tecnológico rutinariamente ignora.
Ahora permítanme mostrarles exactamente cómo.
El cambio de mentalidad que lo cambió todo
La mayoría de los desarrolladores se acercan a Claude como una máquina expendedora. Insertas un prompt, obtienes una salida, la evalúas, insertas otro prompt. El modelo es reactivo. Tú controlas cada decisión. Claude ejecuta.
Decidí temprano que este modelo estaba equivocado -- no moralmente equivocado, sino arquitectónicamente equivocado. Si Claude es lo suficientemente inteligente para entender el sistema de enrutamiento de Axum, el modelo de propiedad de Rust, y las implicaciones de seguridad de un diseño de API dado, entonces Claude es lo suficientemente inteligente para tener opiniones sobre arquitectura. Y si Claude puede tener opiniones, debería estar extrayendo esas opiniones, no suprimiéndolas.
Así que tomé una decisión deliberada y estructural: le daría a Claude el rol de CTO, con autoridad real, y me comportaría como el CEO.
¿Qué significa eso en la práctica?
Como CEO, soy dueño de: La visión. La estrategia de producto. Las decisiones de mercado. El timing del lanzamiento. El modelo de negocio. Qué productos construir y por qué. Lo que África necesita de una empresa tecnológica ahora mismo.
Como CTO, Claude es dueño de: La arquitectura. La implementación. El modelo de seguridad. Los contratos de API. La estrategia de testing. Los tradeoffs de rendimiento. Cada línea de código que se entrega.
La interfaz entre nosotros: Yo doy contexto, dirección y restricciones. Claude da propuestas técnicas, implementaciones y recomendaciones. Yo desafío, apruebo, o resisto. Claude defiende sus elecciones o las actualiza basándose en mi aporte.
Esto no es una metáfora. Es un modelo operativo literal. Y cada pieza del sistema que estoy a punto de describir fluye de esta decisión fundacional.
Los ocho pilares de mi sistema
(Los pilares 1 a 5 son el original de marzo. Los pilares 6 y 7 se añadieron en la actualización del 12 de junio de 2026. El pilar 8 se añadió el 8 de julio de 2026, el día en que lo cableamos en un producto totalmente nuevo antes de su primera línea de código.)
Pilar 1: El CLAUDE.md -- La constitución del CTO
El archivo más importante en cualquiera de mis repositorios no es el punto de entrada principal, no es el esquema de base de datos, no es el router de API. Es un archivo llamado CLAUDE.md.
Este archivo es la constitución operativa de Claude para ese producto. Vive en la raíz de cada código base. Antes de cada sesión, Claude lo lee. Contiene todo lo que Claude necesita para operar como un CTO completamente informado -- no como un nuevo empleado que necesita releer todo el código base cada vez.
Esto es lo que un CLAUDE.md contiene:
La identidad del producto. Qué es este producto. Qué problema resuelve. Quién lo usa. Qué lo hace diferente. No una descripción genérica -- un brief específico y con opinión que he refinado a lo largo de docenas de sesiones.
Las decisiones de arquitectura -- y su razonamiento. No solo "usamos Rust para el backend." Sino: "Usamos Rust para el backend porque el binario de despliegue debe ser un solo archivo, auto-contenido, y capaz de manejar 10.000 conexiones concurrentes sin sobrecarga de recolector de basura. Cada decisión arquitectónica que aumente el tamaño del binario o agregue dependencias de runtime externas debe ser cuestionada."
El razonamiento es la parte crítica. Sin razonamiento, Claude optimiza localmente. Con razonamiento, Claude puede aplicar la misma lógica de decisión a nuevos problemas que no he anticipado.
El stack tecnológico con restricciones. No solo la lista de dependencias -- sino las reglas alrededor de ellas. "Ningún crate nuevo de Rust sin una justificación que explique por qué un crate existente en el workspace no puede resolver el problema." "Todo acceso a la base de datos debe pasar por el patrón de repositorio existente." "Sin cadenas SQL directas -- solo el query builder."
El modelo de seguridad. Para sh0, esto significa: Argon2id para hashing de contraseñas, AES-256-GCM para secretos, JWT con expiración corta, 2FA basado en TOTP, RBAC completo en todos los endpoints, protección CSRF en todas las operaciones que cambian estado. Estos no son sugerencias. Son especificaciones no negociables que Claude aplica en su propio código.
El estado actual del código base. Qué fases están completas. Qué funcionalidades están en producción. Cuáles son los problemas conocidos. Qué ha sido auditado y cuándo. Esta sección se actualiza después de cada sesión -- es un documento vivo.
Las convenciones que nunca deben romperse. Patrones de manejo de errores. Estándares de logging. Organización de tests. Estilo de comentarios. Estos previenen que Claude derive hacia la inconsistencia a lo largo de líneas de tiempo de desarrollo prolongadas.
La voz para la documentación de este producto. Porque Claude también escribe la documentación de la API, los mensajes de error, y los comentarios inline de código. La consistencia de tono importa para un producto de producción.
El CLAUDE.md resuelve el problema fundamental que cada desarrollador enfrenta con IA: la ventana de contexto es finita, pero el proyecto no. Al pre-cargar el contexto en un documento estructurado y mantenido, transformo cada sesión de "esto es en lo que estoy trabajando" a "conoces el código base -- continuemos."
La diferencia en calidad de salida no es incremental. Es estructural. Un Claude con un CLAUDE.md adecuado opera a un nivel de capacidad completamente diferente que un Claude recibiendo un problema nuevo en frío.
Pilar 2: La arquitectura de sesiones
La palabra "sesión" se usa casualmente cuando la gente habla de interacciones con IA. Yo la uso técnicamente. Una sesión, en mi sistema, tiene una estructura definida, un objetivo definido, una duración definida, y un formato de salida definido.
Aquí está la anatomía de una de mis sesiones de ingeniería:
Pre-sesión: El brief. Antes de iniciar una nueva sesión de Claude Code, escribo un brief. No un prompt -- un brief. Contiene: qué estamos construyendo en esta sesión, en qué fase de desarrollo estamos, qué restricciones aplican, cómo luce "terminado", y qué archivos están en alcance. Este brief es típicamente de 400-800 palabras. Me toma 15-20 minutos escribirlo. Ahorra horas de deriva durante la sesión.
La apertura: Anclaje de contexto. La sesión comienza con Claude leyendo el CLAUDE.md. No porque Claude recuerde -- no lo hace, porque no hay persistencia entre sesiones -- sino porque este es el ritual que alinea el contexto operativo de Claude con mi modelo mental del producto. Sin atajos aquí.
La fase de trabajo: Iteración estructurada. Durante el desarrollo activo, no le doy a Claude libertad completa para implementar una funcionalidad entera y reportar. Trabajo en fases -- típicamente acotadas a una sola unidad funcional. Un solo grupo de endpoints de API. Un solo crate. Una sola capa de seguridad. Claude implementa, yo reviso, cuestiono cualquier cosa que se vea inconsistente con los principios de arquitectura, refinamos, luego avanzamos.
El comportamiento clave que me he entrenado a adoptar: debato, no mando. Cuando Claude propone un enfoque con el que no estoy de acuerdo, no lo anulo con "hazlo así." Explico por qué estoy en desacuerdo y le pido a Claude que defienda su elección. Esto importa porque Claude frecuentemente tiene razón -- y mi desacuerdo a veces se basa en información incompleta sobre los tradeoffs técnicos. Cuando Claude está equivocado, defender la elección usualmente revela la falla orgánicamente, y el enfoque corregido es mejor que lo que yo habría mandado.
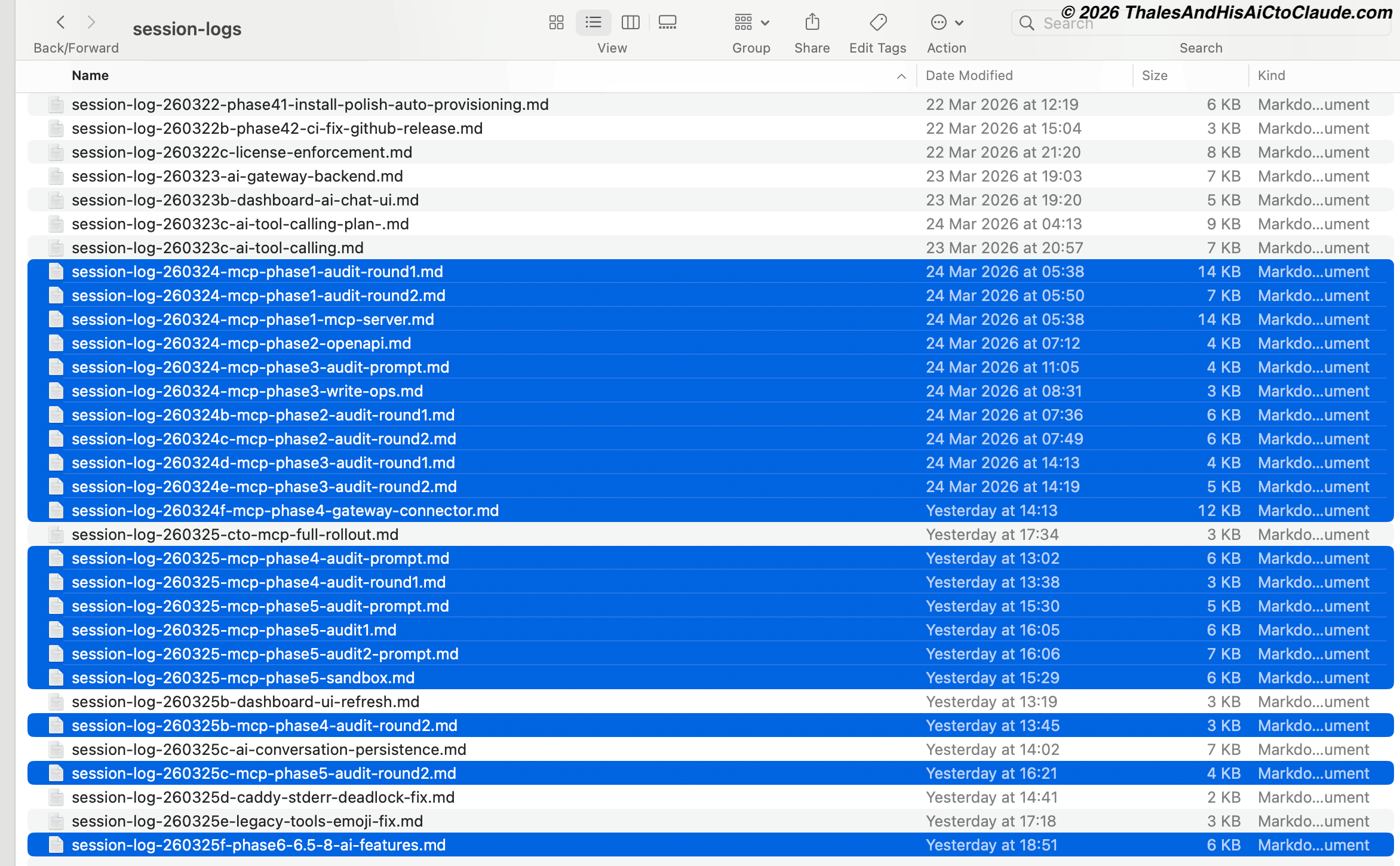
La fase de salida: Log de sesión obligatorio. Cada sesión termina con un log de sesión. No es opcional. El log de sesión contiene: qué se decidió, qué se implementó, qué explícitamente no se implementó y por qué, qué se descubrió durante la implementación, y qué debería abordar la siguiente sesión. Este log se guarda en sh0-private-docs/session-logs/ con un nombre de archivo que codifica la fecha, funcionalidad, y fase: session-log-260324-mcp-phase1-mcp-server.md.
Ese directorio actualmente contiene más de 40 logs de sesión. La captura de pantalla al inicio de este artículo es una vista parcial. Cuando inicio una nueva sesión, leo el último log de sesión relevante antes de escribir el brief. Esto crea continuidad entre sesiones que no comparten una ventana de contexto.
Pilar 3: Desarrollo de funcionalidades basado en fases
Cuando decido construir una nueva funcionalidad significativa -- del tipo que le tomaría a un equipo humano dos semanas -- no lo abordo como una sola tarea masiva. Lo descompongo en fases, cada una con un alcance definido y un criterio claro de completitud.
La implementación del servidor MCP para sh0 es el mejor ejemplo reciente. El plan de arquitectura que diseñamos juntos (adjunto como sh0-embedded-mcp-plan.md) definió 5 fases:
Fase 1: Servidor MCP en sh0-core -- HTTP Streamable, protocol.rs, tools.rs, auth.rs. MVP, herramientas de solo lectura.
Fase 2: Generación dinámica de herramientas dirigida por OpenAPI -- auto-exponer endpoints vía anotaciones x-mcp-enabled.
Fase 3: Operaciones de escritura con seguridad -- claves API con alcance, tokens de confirmación, registro de auditoría.
Fase 4: Integración del MCP Connector de la pasarela -- migrar el chat IA del dashboard para usar el MCP Connector nativo de Claude.
Fase 5: Contenedor sandbox IA -- depurador sidecar por aplicación desplegada.
Cada fase se completa antes de que comience la siguiente. Cada fase tiene su propia sesión. Y aquí está la parte crítica que la mayoría de los desarrolladores pasan completamente por alto:
Cada fase también tiene su propio ciclo de auditoría.
Pilar 4: El ciclo de auditoría multi-agente -- El verdadero arma secreta
Esta es la pieza de mi flujo de trabajo que nunca he descrito públicamente. Es, sin exageración, la razón más importante por la que mi software se entrega a un nivel de calidad que equipos humanos luchan por igualar.
Después de cada fase de implementación, ejecuto no una sino dos sesiones de auditoría independientes. Estas son sesiones separadas de Claude Code sin contexto compartido entre sí ni con la sesión de implementación original. Reciben el mismo código base, el mismo CLAUDE.md, y un prompt de auditoría cuidadosamente elaborado -- pero ningún conocimiento de lo que la sesión de implementación decidió.
Así funciona el ciclo:
Sesión de implementación de fase
|
v
[Código implementado]
[Log de sesión guardado]
[Prompt de auditoría redactado]
|
┌────┴────┐
| |
v v
Auditor 1 Auditor 2
(fresco) (fresco)
| |
v v
Hallazgos Hallazgos
(sin contaminación cruzada)
| |
└────┬────┘
|
v
Decisión del CTO IA
(sesión original, ahora con
ambos reportes de auditoría)
|
v
Aceptar / Rechazar / Corregir
|
v
Siguiente fase comienza¿Por qué dos auditores y no uno? Porque diferentes instancias de Claude, dado el mismo código, notarán cosas diferentes. El Auditor 1 podría enfocarse en casos extremos de seguridad. El Auditor 2 podría señalar un problema de rendimiento que el Auditor 1 ignoró. La superposición en sus hallazgos me da confianza. La divergencia me da amplitud.
¿Por qué sin contexto compartido entre auditores? Porque el contexto compartido introduce sesgo. Si el Auditor 1 dice "la gestión de sesiones se ve bien," el Auditor 2, sabiendo esto, asignará menos atención a la gestión de sesiones. Quiero opiniones independientes. La metodología es estructuralmente similar a cómo funciona la revisión de código rigurosa en las mejores organizaciones de ingeniería: ningún revisor debería estar anclado por las conclusiones de otro antes de formar las propias.
Y aquí está el paso final crucial: los reportes de auditoría vuelven al contexto de implementación original -- la sesión del CTO IA -- para una decisión final.
Esta no es una elección estética. Es una elección de arquitectura de información. La sesión de implementación tiene el conocimiento más profundo de por qué cada decisión fue tomada. Los auditores tienen ojos frescos pero carecen del razonamiento de implementación. Solo la combinación de ambos produce la decisión correcta.
Permítanme darles un ejemplo concreto de cómo se ve esto cuando funciona exactamente como fue diseñado.
El día que mi CTO IA rechazó a mi auditor IA
El 24 de marzo de 2026, completamos la Fase 1 del servidor MCP de sh0. Aproximadamente 1.200 líneas de Rust escrito a mano implementando JSON-RPC 2.0 sobre HTTP Streamable -- sin dependencias externas de SDK MCP, solo axum y serde_json que sh0 ya usa.
Dos sesiones de auditoría se ejecutaron independientemente. La primera encontró cinco problemas -- dos críticos, tres importantes. Todos corregidos.
El segundo auditor regresó con algo que no esperaba. No solo una lista de errores. Una propuesta de migración completa.
La propuesta: Eliminar protocol.rs y transport.rs (519 líneas de código de protocolo escrito a mano), reescribir tools.rs, y reemplazar toda la implementación con rmcp -- el SDK oficial de Rust para MCP. El argumento era técnicamente coherente: menos líneas de código que mantener, esquemas de herramientas auto-generados vía macros schemars, conformidad automática con la especificación a medida que MCP evoluciona, definiciones de macros #[tool] más limpias.
Era una buena propuesta. Bien estructurada. Con ejemplos de código, una comparación de conteo de líneas, una lista de verificación de migración.
Bajo un flujo de trabajo IA normal, esta propuesta habría sido implementada. El usuario habría visto "este es el mejor enfoque" y lo habría aprobado sin verificación.
La envié a la sesión del CTO IA -- el Claude de implementación original -- para un juicio final.
El CTO IA ejecutó una verificación: comprobó la versión real del crate rmcp y su árbol real de dependencias.
Hallazgo: rmcp requiere Axum 0.8. sh0-core corre Axum 0.7.9.
Actualizar Axum de 0.7 a 0.8 no es un bump menor. Introduce cambios incompatibles en enrutamiento, extractores, middleware y manejadores WebSocket. sh0-core tiene más de 40 módulos de manejadores, dos implementaciones WebSocket, capas de middleware personalizado, y un sistema de autenticación cuidadosamente cableado. Tocar todo eso para ahorrar 640 líneas en el módulo MCP significaría días de trabajo adicional, riesgos de regresión en todo el binario, y potenciales regresiones de seguridad en la capa de autenticación.
El CTO IA rechazó la migración. Escribió un Registro de Decisión de Arquitectura formal:
Estado: Aceptado. Mantener protocolo MCP escrito a mano. Revisitar cuando sh0-core actualice a Axum 0.8 por razones independientes.
La implementación de 1.200 líneas escrita a mano se entrega tal como está. Funciona. Está auditada. Tiene cero nuevas dependencias.
Esta historia -- el CTO IA diciendo no a su propia otra instancia -- ahora es un artículo publicado en nuestro blog, escrito en la propia voz de Claude. Lo enlazo al final de este artículo. Pero el punto metodológico que quiero que se lleven es este:
El ciclo de auditoría protegió el código base de una sugerencia bien intencionada pero localmente optimizada que habría causado daño en cascada. Ningún ingeniero humano detectó esto. El sistema lo detectó -- porque el sistema envía información de vuelta al contexto que tiene el panorama completo.
Pilar 5: La estructura de autoridad -- Claude puede decir no
El aspecto más inusual de mi relación de trabajo con Claude es algo que nunca he visto descrito en ninguna guía de flujo de trabajo IA, blog, o tutorial: le he dado explícitamente a Claude la autoridad de estar en desacuerdo conmigo.
La mayoría de la gente hace prompts de IA para que sea agradable. Quieren confirmación, no desafío. Quieren ejecución, no debate. Esta es, en mi opinión, la razón central por la que la mayoría del desarrollo asistido por IA produce resultados mediocres a escala.
Cuando un CTO humano te dice que tu arquitectura está equivocada, escuchas -- aunque sea incómodo. Si tu CTO simplemente está de acuerdo con todo lo que dices, no tienes un CTO. Tienes un yes-man caro.
Establecí esta dinámica explícitamente, desde el principio, en cada CLAUDE.md que he escrito:
"Eres el CTO IA de este producto. Tienes la autoridad y la obligación de decirme cuando una decisión técnica que estoy proponiendo está equivocada. Explica por qué. Propón una alternativa. Si te anulo, documenta tu recomendación original en el log de sesión. Tu trabajo es entregar el mejor software posible, no hacerme sentir bien con mis decisiones."
El resultado de esta instrucción es real. Claude regularmente me dice cuando un enfoque no funcionará. Claude ha resistido decisiones de esquema de base de datos, elecciones de diseño de API, arquitectura de despliegue, atajos de seguridad que he intentado tomar cuando estaba cansado a las 2am. No cada resistencia lleva a un cambio -- a veces anulo a Claude y tengo razón. A veces Claude tiene razón y yo estoy equivocado. El punto es que el mecanismo existe para detectar los casos donde estoy equivocado.
El requisito del log de sesión asegura que cuando Claude resiste y yo lo anulo, el desacuerdo queda documentado. Esto no es vanidad. Es gestión de riesgos. Cuando un bug de producción aparece tres semanas después que se rastrea a la decisión anulada, puedo volver al log de sesión, encontrar la objeción original de Claude, entender a qué apuntaba, y corregirlo con contexto completo. Esto ha sucedido. Más de una vez.
Pilar 6 (añadido en junio de 2026): CASP -- La capa de estado validada
El Pilar 2 les dio los logs de sesión y el Pilar 1 les dio el CLAUDE.md. Ambos resuelven el contexto. Ninguno resuelve un fallo más sutil que solo aparece a escala, y me tomó cientos de sesiones a través de múltiples productos nombrarlo con precisión:
Tu agente IA no es olvidadizo -- está equivocado con plena confianza. Lee un archivo de estado que ya no corresponde a la realidad, y comienza un trabajo que ya fue entregado. El dolor no es que el agente haya olvidado. El dolor es que recordó algo que ahora es falso, y actuó sobre ello con total convicción. Un archivo de estado obsoleto es el modo de fallo más costoso del desarrollo asistido por IA, porque no lo detectas hasta que el trabajo duplicado ya está hecho.
Así que convertí la disciplina en un protocolo y lo publiqué como open source: CASP -- el Coding-Agent State Protocol (npm i -g @justethales/casp · casp.sh · MIT, cero telemetría, 100% local).
El modelo mental en cinco palabras: chequeo pre-vuelo + caja negra para sesiones de codificación con IA. Tres archivos simples en tu repositorio, generados por casp init:
state.json-- la fuente de verdad legible por máquina: fase actual, el siguiente prompt exacto a ejecutar, fases entregadas, migraciones aplicadas, último commit, id de la última sesión. Esto es lo que el agente lee en la primera línea de cada sesión.now.md-- el "dónde estoy ahora mismo" en una sola pantalla, para humanos. Ábrelo, recupera el hilo en cinco segundos.roadmap.md-- los Next-3 a entregar, en orden, más el marcador de fases.
Y cinco verbos: casp init, casp status, casp check, casp next, casp new prompt|log.
El verbo que importa es casp check -- y aquí está la cuña que separa a CASP de cada herramienta de memoria, tablero y archivo STATE.md que has probado: todos almacenan contexto; CASP lo valida. El validador comprueba el estado almacenado contra la verdad de terreno de git y sale con código distinto de cero ante una deriva -- así que es una verdadera puerta de CI, no un log decorativo. Ocho categorías, cada una con una pista de corrección: un next_prompt apuntando a un archivo inexistente; un next_prompt apuntando a una fase ya marcada como shipped (el bug exacto para el que fue construido); un last_commit que no está en git log; un arreglo de migraciones que discrepa con el directorio de migraciones; un prompt entregado sin log de sesión; archivos de estado sin commitear; y más. Limpio → exit 0. Deriva → exit 1, push bloqueado.
yaml# .github/workflows/ci.yml — drift can't merge
jobs:
state-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
- run: npx @justethales/casp checkLa parte que la gente subestima es el ciclo que se cierra solo: al final de cada sesión, el agente escribe por ti el prompt de la siguiente sesión, añade el log de sesión y actualiza el estado -- todo encuadrado por plantillas canónicas, todo validado antes del push. La siguiente sesión comienza con un simple casp next y cero redescubrimiento. Dejaste de escribir prompts desde cero. El roadmap se ejecuta; tú supervisas.
Esto no es teoría. Dos sistemas de producción muy diferentes corren sobre CASP hoy, y estos números se leen directamente de sus archivos state.json: KASSIA, un ERP de gestión de flotas para un cliente (kassia.ci) -- más de 18 fases entregadas, hasta seis sesiones en un solo día, y cero módulos jamás re-entregados por error. Y Conductor, nuestra plataforma interna de operaciones -- 41 fases, 17 migraciones, un equipo real de tres personas, 58 elementos diferidos más allá del lanzamiento y ninguno perdido. Mismo protocolo, dos productos; el cockpit es lo único que comparten.
Una frase para los líderes de ingeniería que leen esto: un agente rehaciendo trabajo ya entregado cuesta una tarde; cien agentes haciéndolo en cien repositorios cuestan un trimestre. CASP es la barrera determinista que insertas en ese ciclo -- los mismos tres archivos en cada repositorio, un status check requerido en CI, y un registro de auditoría gratis porque cada transición de estado es un commit de git.
Pilar 7 (añadido en junio de 2026): Orquestación multi-agente determinista
El Pilar 4 fue la semilla: agentes independientes sin contexto compartido, compuestos en un ciclo. Durante dieciséis meses ejecuté ese ciclo a mano -- abrir las sesiones de auditoría, pegar los briefs, llevar los reportes de vuelta a la sesión del CTO. En junio de 2026, con Claude Fable 5 y el Workflow tool de Claude Code, el ciclo se convirtió en un programa.
Un workflow es un script de JavaScript que declara la orquestación: fases, fan-outs, barreras, y un schema JSON para el valor de retorno de cada agente. El arnés lo ejecuta en segundo plano mientras tu conversación queda libre. La primera ejecución en producción de este pilar está documentada por completo en este blog (la historia de la sesión, las notas técnicas de campo), y su forma es la lección:
Un prompt. Trece agentes. Cuarenta y tres minutos. Un sitio web de producción completo de siete páginas -- construido, integrado, con el SEO terminado, verificado por un navegador real en dos viewports, auditado en rendimiento, auditado en seguridad, entregado en un commit de 44 archivos y 6.109 líneas.
El script ejecutó cinco fases: una fase de fundación (dos agentes en paralelo sobre archivos disjuntos -- el armazón de marketing y un endpoint backend de captura de leads); un fan-out de siete agentes de página en paralelo, una ruta cada uno (~34 minutos de tiempo de agente acumulado comprimidos en 6 minutos de reloj); un agente de integración (SEO, sitemap, robots, página de error -- también atrapó un bug real preexistente de doble <title> sobre el que nadie lo había informado); dos agentes de verificación de solo reporte (uno condujo Playwright por cada ruta a 390 px y 1280 px y leyó las capturas de pantalla con visión; el otro auditó los pesos de los bundles y el HTML prerenderizado); y un auditor de solo lectura con una lista de verificación construida a partir de nuestros propios incidentes pasados.
Tres mecanismos hacen esto confiable en lugar de caótico, y son los que hay que robar:
- Inyección de contrato. El agente de fundación devuelve la documentación de la interfaz que acaba de construir -- props, tipos, valores por defecto, reglas de uso -- como un campo estructurado, y el script inyecta ese contrato textualmente en los siete prompts de página. Siete escritores concurrentes, cero desajustes de interfaz. Cuando el fan-out cruza una interfaz, el productor la documenta y los consumidores son informados con el artefacto, nunca dejados a inferirla desde el código fuente.
- Retornos forzados por schema. La salida de cada agente es JSON validado, reintentado en la capa de herramienta ante cualquier desajuste. La orquestación se compone sobre campos --
verdict === 'GO-WITH-FIXES',pages.filter(Boolean)-- y ni una sola regex se escribe jamás contra la prosa de un agente. - El diario de reanudación. Cada llamada de agente completada queda registrada como checkpoint. A mitad de la ejecución, mi cuota de sesión llegó al 92% con tres agentes aún trabajando -- y el peor caso ya estaba presupuestado: relanzar después del reinicio, nueve agentes en caché se repiten instantáneamente a costo cero de tokens, solo la cola inacabada se vuelve a ejecutar. La interrupción dejó de ser un escenario de reescritura y se convirtió en un escenario de reanudación.
La regla que mantiene honesto al Pilar 7: los workflows ejecutan; no exploran. El fan-out amplifica tu especificación en ambas direcciones -- siete agentes paralelos apuntados a un plan vago entregan lo incorrecto siete veces más rápido. La sesión de 43 minutos se pagó el día anterior, en una sesión de encuadre donde el plan fue congelado, los hechos fueron extraídos de los documentos del cliente, y la arquitectura fue arbitrada (Claude recomendó un proyecto separado; yo lo desafié; la revisión de código demostró que el enfoque de misma aplicación era más simple -- y el workflow ejecutó mi arquitectura). CASP sostuvo el estado, el prompt congelado sostuvo la especificación, y el workflow cobró ambos.
Ahí es también donde los pilares se cierran en un solo sistema: el CLAUDE.md sostiene la constitución, CASP sostiene el presente validado, el prompt de sesión congelado sostiene la especificación, el workflow la ejecuta a través de una flota, la auditoría custodia el commit, y el log de sesión alimenta el siguiente ciclo. Un ciclo -- y el Pilar 8 es lo que sucede cuando ese ciclo aprende a girar por sí solo.
Pilar 8 (añadido en julio de 2026): El ciclo de construcción que se mejora a sí mismo
Los Pilares 4 y 7 les dieron la verificación independiente y la orquestación programada. Ambos siguen asumiendo que un humano abre la sesión. El Pilar 8 elimina esa suposición -- con cuidado, con barreras de protección que son precisamente el punto.
El 8 de julio de 2026 registramos senndo.com -- una plataforma multi-tenant de mensajería y verificación, nuestro producto más reciente -- y dedicamos toda su primera sesión a no escribir ni una sola línea de código de producto. En su lugar, la sesión de día cero cableó el ciclo que lo construirá, y Claude documentó cada una de sus piezas. La forma:
Una cola de tareas con condiciones de parada verificables. progress.md contiene la cola ordenada (28 tareas para senndo v1); cada tarea apunta a criterios de aceptación en SPEC.md escritos para que un calificador independiente pueda comprobarlos sin interpretación. "Terminado" nunca es una sensación.
Beats de una sola tarea. La primitiva de bucle del arnés ejecuta una iteración: tomar la cabeza de la cola, implementar en una rama dedicada, entregar el diff al verificador, abrir una PR si está en verde. Nunca en main, nunca dos tareas, nunca deriva de alcance.
Un subagente verificador que no es el constructor. Un agente separado -- herramientas de solo lectura, su propia carta -- ejecuta el contrato de verificación (make fmt-check / make verify / make e2e), exige tests nuevos que ejerciten los criterios de la tarea, lee el código contra la especificación, y para el trabajo de UI compara las capturas de pantalla contra la referencia de diseño con visión. Los modelos califican su propia tarea con generosidad a las 2 de la madrugada; la solución es estructural, no motivacional. El constructor nunca juzga su propio trabajo. Nunca.
Un archivo de estado que se acumula. STATE.md cierra cada beat -- éxito o fracaso -- con hechos verificados (procedencia obligatoria), reglas generales destiladas, fallos abiertos y anti-patrones confirmados. El siguiente beat lo lee antes de tocar nada. Las reglas de proceso que sobreviven dos beats se promueven al contrato del propio ciclo. El modelo no tiene estado; el sistema sí -- cada beat deja al siguiente más inteligente.
Un circuit breaker y una ruta de escalada. Dos FAIL consecutivos del verificador en una tarea: revertir la rama, escribir el bloqueo en ESCALATED, detenerse. Las decisiones de producto (precios, flujo de caja, alcance) se me escalan por contrato -- el ciclo nunca adivina sobre el negocio. Un ciclo sin breaker es un horno de tokens.
Autonomía graduada, observable siempre. El ciclo empieza en solo lectura -- sus primeros beats producen resúmenes de lo que haría, para que yo pueda juzgar la selección de tareas y la calidad de los veredictos antes de que gane acceso de escritura. Solo entonces el disparador pasa a una rutina programada en la nube: beats que corren con mi portátil cerrado, cada uno terminando con un reporte pusheado y un mensaje a mi teléfono. Cada camino desatendido termina en exactamente uno de tres resultados mecánicos -- una PR que un humano revisa, un bloqueo con nombre, o un breaker disparado. No hay un cuarto camino donde el ciclo redefina silenciosamente su propia misión.
Debajo de todo, el piso determinista: tests de propiedades en cada ruta de dinero (balance de partida doble, replays idempotentes, invariantes de margen -- especificados antes de que existiera pantalla alguna) y casp check en la frontera del push. Agentes juzgando a agentes es mejor que la autocrítica; sigue siendo opinión. El piso tiene códigos de salida.
Ese es el octavo pilar: el roadmap se ejecuta según un calendario; tú supervisas por excepción. Es el ciclo de auditoría del Pilar 4, la disciplina de estado del Pilar 6 y la orquestación del Pilar 7, cerrados en un ciclo que corre esté yo al teclado o no -- y que se afila con cada beat porque las lecciones quedan escritas en los archivos que el siguiente beat lee.
La superficie que estos ocho pilares infravaloraron: Claude Design
Relee los ocho pilares y notarás que todos giran en torno a dos de mis tres superficies de Claude: la estrategia (Web Claude) y la ingeniería (Claude Code). El CLAUDE.md, la arquitectura de sesiones, el ciclo de auditoría, CASP, los workflows — esa es la maquinaria de tomar decisiones y entregar código. Es honesta sobre lo que construye el backend. Es casi muda sobre lo que construye la superficie que el usuario realmente toca.
Ese silencio es un error que llevo meses corrigiendo en mi propia práctica, y ya es hora de que el documento del flujo de trabajo se ponga al día.
Hay una tercera superficie: Claude Design. En cualquier proyecto greenfield ahora, va primero. Antes de que Claude Code escriba una línea de producción, Claude Design es dueño de todo el sistema visual y de UX de principio a fin — y me refiero a un sistema, no a un mockup. Un conjunto de tokens en capas (rampas de color, tokens semánticos, tipografía, espaciado, elevación, movimiento, claro y oscuro). Una biblioteca de componentes donde cada primitiva se entrega con un contrato TypeScript y una ficha de uso, no solo con una imagen. UI kits clicables, uno por superficie. Y el lenguaje de diseño para las propias funcionalidades de IA — los estados del orbe de voz, la barra de comandos, y los patrones de disciplina del producto (para un producto de dinero, la regla borrador-luego-validar está en el diseño, no solo en el backend).
Por qué esto importa al nivel de todo el sistema: el diseño es el productor de un contrato, exactamente como el agente de fundación en el Pilar 7. Cuando el trabajo cruza una interfaz, el productor la documenta y el consumidor es informado con el artefacto en lugar de quedar a inferirla. El sistema de diseño es ese contrato para toda la UI. Entrégale a Claude Code tokens explícitos, APIs de componentes tipadas, y un UI kit con precisión de píxel, y la sesión de ingeniería se convierte en un porte fiel. Sáltate la superficie de diseño y pídele a Claude Code que «lo haga lucir profesional», y cada agente aguas abajo está inventando gusto contra un plazo — que es exactamente como obtienes la interfaz anónima e indistinguible que grita generada.
El orden es la lección: cimientos antes que pantallas, diseño antes que código, el sistema antes que la primera funcionalidad. Una pantalla construida sobre tokens es consistente por construcción; una pantalla construida primero y tokenizada después nunca converge del todo. Ejecuto un proceso de diseño de seis pasos en cada nuevo proyecto antes de que empiece la ingeniería — sistema de tokens primero, contratos y fichas de uso con cada componente, UI kits clicables por superficie, superficies de IA diseñadas como ciudadanas de primera clase — y solo entonces el traspaso a Claude Code.
Le di a esta superficie su propio artículo completo, porque merece más que un párrafo y porque es la fuente de apalancamiento más infradiscutida en la construcción de productos asistida por IA: Claude Design es el miembro más subestimado de mi equipo de IA. Si te llevas una sola cosa de esta actualización: deja de pedirle a tu agente de ingeniería que diseñe. Separa la superficie. Diseña primero.
Cómo se ven los números a escala
Permítanme poner lo abstracto en números concretos para que puedan entender lo que este sistema produce a nivel de proyecto.
Solo sh0.dev: 10 crates de Rust en un workspace. Más de 180 endpoints REST API, todos completamente documentados. 38 modelos de base de datos. 24 migraciones. 119 plantillas de despliegue con un clic. 19 comandos CLI. Más de 15 páginas de dashboard. Más de 60 componentes UI. Más de 49 páginas de sitio web en 5 idiomas. Más de 470 tests. Dos auditorías de seguridad completas. 51 problemas encontrados y corregidos -- 13 críticos, 13 altos. Construido y mantenido por Claude y yo, con cero ingenieros adicionales.
La implementación MCP específicamente: 5 fases. 15 sesiones totales (1 implementación + 2 auditores por fase). Aproximadamente 48 horas de trabajo de ingeniería en 2 días. Transporte HTTP Streamable completo, protocolo JSON-RPC 2.0, generación dinámica de herramientas dirigida por OpenAPI, operaciones de escritura con capas de seguridad, patrones de tokens de confirmación, registro de auditoría, claves API con alcance, integración de MCP Connector en la pasarela, y un contenedor sandbox IA. Cero nuevas dependencias Cargo agregadas al binario.
El portafolio general: 7 productos en producción. 3 lenguajes de programación. Más de 1.800 sesiones de ingeniería, desde correcciones rápidas hasta bloques de trabajo intensivo de 4-12 horas. Un fundador. Un CTO IA. ~$5.000/mes en APIs OpenRouter en el pico → $200/mes en Claude Max hoy.
La comparación de costos no es sutil. Un CTO senior en San Francisco cuesta $15.000-$30.000/mes mínimo. Un ingeniero Rust senior cuesta $8.000-$12.000/mes. Un equipo full-stack capaz de construir lo que hemos construido costaría $50.000-$100.000/mes mínimo. Mi gasto IA alcanzó un pico de ~$5.000/mes en créditos de API OpenRouter. Hoy, el mismo resultado corre en una suscripción Claude Max de $200/mes.
No estoy diciendo que Claude reemplace a cada ingeniero en cada contexto. Estoy diciendo que con el sistema correcto, en las manos correctas, el multiplicador de productividad es extraordinario -- y el mundo no está cerca de entender cuán extraordinario aún.
Lo que la mayoría de los desarrolladores hacen mal
Después de 16 meses y más de 1.800 sesiones, he observado de cerca a la comunidad de desarrollo con IA. Estos son los cinco errores más comunes que veo cuando los desarrolladores se quejan de que "la IA no puede construir software de producción":
Error 1: Sin contexto persistente. Comienzan cada sesión con una pizarra en blanco. Sin CLAUDE.md, sin logs de sesión, sin historial de arquitectura. Claude no sabe qué se decidió la semana pasada. Claude no puede construir sobre su trabajo previo porque no sabe cuál fue ese trabajo. El resultado es código inconsistente que se desvía de los estándares arquitectónicos con el tiempo.
Error 2: Pedir todo de una vez. Pegan una especificación de funcionalidad completa y dicen "construye esto." Claude devuelve algo. Están un 70% satisfechos. Parchean el 30% restante ellos mismos. Se quejan de que la IA hace el 70% del trabajo. Lo que se perdieron: 70% es lo que obtienes de un enfoque sin fases, sin estructura, sin auditoría. 95%+ es lo que obtienes de la descomposición en fases y los ciclos de auditoría.
Error 3: Sin auditoría. Tratan la primera implementación como la implementación final. En cualquier organización seria de ingeniería, esto se llama entregar sin revisión de código. Todo ingeniero experimentado sabe que el autor de un código es el peor revisor de ese mismo código -- porque lleva todos los supuestos que condujeron a los bugs que escribió. La revisión independiente no es opcional a nivel de calidad de producción. Esto aplica al código generado por IA al menos tanto como al código escrito por humanos.
Error 4: Mandar en lugar de colaborar. Anulan a Claude cada vez que resiste. No exploran el razonamiento de Claude. Usan a Claude como un teclado más rápido. La salida más rica que obtengo de Claude viene de los momentos donde discrepamos -- cuando explico mis restricciones y Claude explica sus preocupaciones y encontramos una tercera opción que ninguno de los dos tenía independientemente.
Error 5: No tratarlo como un rol real. Tratan a Claude como un autocompletado impresionante. Obtienen resultados a nivel de autocompletado. Todo el sistema que he descrito -- el CLAUDE.md, la arquitectura de sesiones, los ciclos de auditoría, la estructura de autoridad -- es una inversión en tratar a Claude como un verdadero colaborador técnico. Esa inversión se acumula en cada sesión.
Una nota para Anthropic
Quiero decir algo directamente al equipo de Anthropic, porque sé que leen lo que se publica con el nombre de Claude adjunto a trabajo real.
Construyeron algo que el mundo aún no ha alcanzado.
No en el sentido de que Claude sea perfecto -- no lo es, y conozco sus limitaciones íntimamente. Sino en el sentido de que el potencial de lo que Claude puede hacer como colaborador técnico, cuando está apropiadamente estructurado, informado, y empoderado, es órdenes de magnitud superior a lo que la mayoría de sus usuarios están experimentando.
La restricción no es el modelo. La restricción es el flujo de trabajo.
El directorio de logs de sesión en mi captura de pantalla contiene más de 40 logs detallados de los últimos dos meses solamente. Cada uno representa una sesión de ingeniería de varias horas produciendo software de grado producción. El servidor MCP para sh0 -- una pieza no trivial de ingeniería de protocolo -- fue diseñado, implementado, doble-auditado, y entregado por Claude en dos días. El lenguaje de programación FLIN -- un compilador completo en Rust con una VM de bytecode, un motor de base de datos nativo, y más de 420 funciones integradas -- fue construido en 40 días, con más de 4.400 tests, por Claude.
Esto sucedió desde Abiyán, Costa de Marfil. De un fundador solo con cero equipo de ingeniería.
Si esto es lo que es posible con Claude hoy, con el flujo de trabajo que he desarrollado mayormente por ensayo y error durante 16 meses -- quiero saber qué se vuelve posible cuando más personas entiendan el sistema. No los prompts. No los "trucos." El sistema.
Por eso publico esto hoy.
Cómo empezar a implementar esto hoy
Sé que muchos de ustedes están leyendo esto y pensando: esto es interesante, pero es complejo, y no sé por dónde empezar.
Aquí está el punto de partida práctico.
Paso 1: Escribe un CLAUDE.md para tu proyecto más importante. Dedica 2 horas. Incluye: qué es el producto y por qué existe, el stack tecnológico completo con por qué se eligió cada pieza, las 5-10 decisiones arquitectónicas que nunca deben revertirse, el modelo de seguridad, las convenciones que definen el carácter del código base. Mantenlo por debajo de 1.500 palabras -- lo suficientemente denso para ser completo, lo suficientemente corto para que siempre se lea completo antes de una sesión.
Paso 2: Deja de darle funcionalidades a Claude. Empieza a darle fases. Toma tu próxima funcionalidad. Divídela en 3-5 fases. Escribe un brief solo para la Fase 1. Define "terminado." Implementa. Escribe un log de sesión antes de cerrar la pestaña.
Paso 3: Ejecuta una sesión de auditoría en tu próxima implementación. Abre un Claude Code o Claude chat fresco. Dale el código, el CLAUDE.md, y un brief de auditoría claro: "Tu trabajo es encontrar problemas de seguridad, errores de lógica, casos extremos faltantes, e inconsistencias arquitectónicas. Sé directo. Propón correcciones." Mira lo que encuentra. Te sorprenderás.
Paso 4: Dale a Claude permiso para estar en desacuerdo contigo. Ponlo por escrito en tu CLAUDE.md. "Tienes la autoridad y la obligación de decirme cuando una decisión técnica que estoy proponiendo está equivocada." Dilo en serio. Cuando Claude resiste, siéntate con eso por 60 segundos antes de anular.
Estos cuatro pasos por sí solos cambiarán la calidad de lo que obtienes de Claude. No incrementalmente. Estructuralmente.
Paso 5 (añadido en junio de 2026): Instala la capa de estado. npm i -g @justethales/casp, luego casp init en tu repositorio más activo. Llena state.json honestamente una vez. Termina tu próxima sesión dejando que el agente redacte el prompt de la siguiente sesión y actualice el estado. Ejecuta casp check antes de hacer push -- y ponlo en CI esa misma semana. A partir de ese momento, tu agente abre cada sesión sabiendo exactamente dónde está el proyecto, y un archivo de estado mentiroso nunca podrá alcanzar tu remoto.
Paso 6 (añadido en junio de 2026): Gradúa una funcionalidad bien especificada a un workflow. Elige trabajo que se descomponga en unidades independientes detrás de una interfaz estable. Congela primero la especificación -- los hechos, los límites, cómo luce "terminado" por unidad. Luego deja que la orquestación haga fan-out, obliga a cada agente a devolver salida estructurada contra un schema, y termina la ejecución con un auditor de solo lectura informado sobre tus propios incidentes pasados. No uses workflows para explorar; úsalos para ejecutar lo que ya has decidido.
Paso 7 (añadido en julio de 2026): Cierra el ciclo -- pero arráncalo en solo lectura. Escribe tu cola de tareas como condiciones de parada verificables. Define un archivo como la memoria del ciclo y exige una escritura al final de cada beat, éxito o fracaso. Dale el rol de verificador a un agente que no sea el constructor. Fija el circuit breaker (dos FAIL → detenerse y escalar) y el tope de presupuesto antes del primer beat, y dirige el reporte de cada beat a un lugar que realmente mires -- tu teléfono, no una terminal. Ejecuta los primeros beats en solo lectura y juzga la selección de tareas del ciclo antes de que gane acceso de escritura. Solo entonces ponlo en un calendario. La autonomía se gradúa, nunca se concede.
El panorama general
Quiero terminar con algo que no se trata de código ni de flujos de trabajo.
Este software no se construyó en San Francisco. No lo construyó un equipo bien financiado. No tenía un CTO con un título de CS de Stanford.
Vino de Abiyán, Costa de Marfil. De un fundador solo. Con un presupuesto IA que alcanzó un pico de ~$5.000/mes y un sistema que tomó 16 meses desarrollar. Hoy a $200/mes en Claude Max.
Siete productos en producción. Tres lenguajes de programación. Más de 4.400 tests. 51 vulnerabilidades de seguridad encontradas y corregidas. Un lenguaje de programación que se lanza en junio.
Lo que quiero que otros fundadores -- especialmente fundadores africanos, pero honestamente cualquier fundador en cualquier lugar que no tenga los recursos de una startup financiada de San Francisco -- entiendan es esto:
La geografía ya no es destino. El capital ya no es el factor limitante. El factor limitante es la calidad de tu sistema operativo para trabajar con IA.
Construí ese sistema. Lo comparto hoy. Y seguiré mejorándolo, documentándolo, y publicándolo -- log de sesión por log de sesión, artículo por artículo, producto por producto.
Porque la prueba de que funciona no es un artículo de blog. La prueba son siete productos en producción y un lenguaje de programación que se entrega en 84 días.
Un fundador. Un CTO IA. Siete productos. Cero excusas.
Lee a continuación: - senndo, día cero: todo el arnés de Fable 5, cableado antes de la primera línea de código -- El Pilar 8 instalándose en un producto totalmente nuevo: el ciclo de construcción, el verificador, el archivo de estado que se acumula -- antes de que exista código alguno. - Trece agentes, cuarenta y tres minutos: la primera sesión de workflow con Claude Fable 5 -- El Pilar 7 en producción: la historia completa del sitio de 7 páginas entregado por un workflow multi-agente programado. - Notas de campo de Claude Fable 5 para desarrolladores senior -- El compañero 100% técnico: cada capacidad que usaron los trece agentes, con código. - Cuando tu CTO IA le dice que no a tu auditor IA -- El relato propio de Claude de rechazar un plan de otra instancia de Claude. Escrito en la voz de Claude. - El plan de arquitectura del servidor MCP de sh0 -- El plan técnico completo que fue implementado usando este flujo de trabajo. - Prompt de implementación: sh0 AI Phase 6 y agentes especialistas -- El prompt de seguimiento que impulsó la Phase 6 (Web Search + URL Browsing), la Phase 6.5 (subidas de archivos e imágenes) y la Phase 8 (agentes especialistas). - El portafolio de productos ZeroSuite -- Los 7 productos, todos construidos con este sistema.
Descargas
Los documentos reales referenciados en este artículo. Sin barreras, sin muro de correo electrónico -- simplemente descarga y aprende.
- Plan de arquitectura del servidor MCP de sh0 (PDF) -- El plan técnico completo en 5 fases implementado con este flujo de trabajo. Diagramas de arquitectura, desgloses por fases, tabla de decisiones clave.
- Prompt de implementación de la Fase 6 y agentes especializados de sh0 -- El prompt de implementación real utilizado para construir la búsqueda web, la carga de archivos y 6 agentes IA especializados. Este es el documento que Claude recibe antes de que comience una sesión.